Loading…
Loading video…
70,000 views

Ever wondered how Netflix predicts which shows you'll love with just a few clicks? Distributions to estimate population parameter make this possible by helping statisticians draw conclusions about entire populations from small samples. When the FDA tests a new medication on 1,000 patients to determine its effectiveness for all Americans, they're using these statistical distributions to make confident estimates. The concept of Distributions To Estimate Population Parameter Explained involves choosing between z, t, chi-square, and F distributions based on what information is available about your data. Watch the full video on JoVE Coach to master this concept with expert-led visuals and step-by-step explanations.
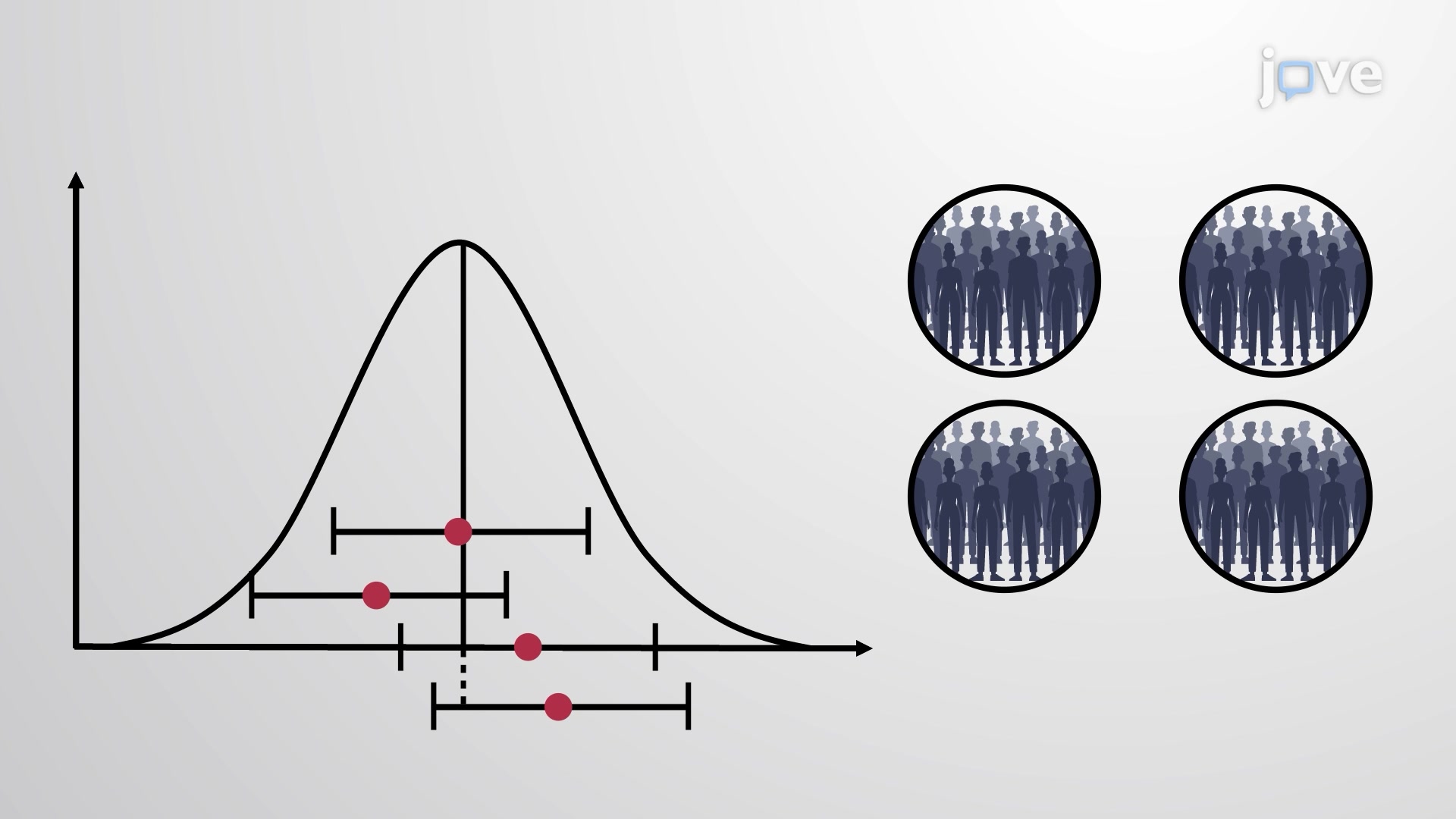
Statistical inference relies on our ability to make educated guesses about entire populations based on limited sample data. When pollsters survey 1,200 Americans to predict election outcomes for 240 million eligible voters, they're applying the principles of parameter estimation. The challenge lies in selecting the appropriate statistical distribution that best reflects the underlying data characteristics and sampling conditions.
The z-distribution becomes your go-to tool when estimating population proportions or means with known population standard deviations. For instance, if quality control engineers at Boeing know the historical standard deviation of aircraft part measurements, they can use z-distribution to estimate the true population mean from current sample data. This distribution assumes normal population characteristics and relies on the Central Limit Theorem for samples larger than 30.
However, most real-world scenarios involve unknown population standard deviations. Here's where the t-distribution shines. When medical researchers study the effectiveness of a new diabetes treatment without knowing the population's blood sugar variation, they turn to t-distribution. This distribution accounts for the additional uncertainty introduced by estimating the population standard deviation from sample data, making it more conservative and reliable for smaller sample sizes.
Chi-square and F distributions handle situations where normality assumptions break down. The chi-square distribution proves invaluable when analyzing categorical data or testing variance assumptions. Market researchers examining consumer preferences across different demographic categories often rely on chi-square tests to estimate population parameters from survey data.
F-distribution comes into play when comparing variances between groups or in analysis of variance (ANOVA) procedures. Educational researchers comparing standardized test score variations across different teaching methods use F-distribution to estimate population variance ratios and make informed conclusions about educational effectiveness.
These concepts appear frequently on AP Statistics exams, college statistics courses, and professional certification tests like the MCAT. Students must understand not just the mathematical mechanics but also the decision-making process for selecting appropriate distributions. The key lies in systematically evaluating sample size, known versus unknown parameters, and distribution shape assumptions before proceeding with estimation procedures.
Frequently Asked Questions
Distributions to estimate population parameter are statistical tools that help us make educated guesses about entire populations using limited sample data. They're essential because we rarely have access to complete population data, yet need to make reliable inferences for decision-making in business, healthcare, and research.
Start by checking three key conditions: sample size, whether population standard deviation is known, and if data appears normally distributed. Use z-distribution for known standard deviation or large samples, t-distribution for unknown standard deviation, and chi-square or F for non-normal or categorical data.
The main difference lies in whether you know the population standard deviation. Z-distribution requires known population standard deviation, while t-distribution is used when you must estimate it from sample data. T-distribution produces wider confidence intervals to account for this additional uncertainty.
MCAT questions typically present research scenarios requiring you to identify appropriate statistical methods for analyzing study results. You'll need to recognize when researchers should use different distributions based on study design, sample characteristics, and measurement types.
The U.S. Census Bureau uses chi-square distribution when analyzing demographic data across different categories, such as estimating the true distribution of educational attainment levels across various ethnic groups based on survey samples.
While the mathematical formulas can seem complex, the conceptual understanding is quite accessible. Focus first on understanding when to use each distribution type, then gradually build comfort with the calculations through practice problems.
Create a decision flowchart listing the conditions for each distribution type, then practice applying it to varied scenarios. Focus on identifying key characteristics like sample size, known parameters, and data distribution shape rather than memorizing formulas.
Move on to hypothesis testing, which builds directly on parameter estimation concepts. You'll also want to explore confidence interval interpretation, Type I and Type II errors, and analysis of variance (ANOVA) procedures.
Related Micro-courses
Related Subjects
















