Loading…
Loading video…
130,604 views

Ever wonder how medical researchers determine if a new drug actually works, or how pollsters know their election predictions are reliable? The p value serves as the statistical gateway that helps scientists and researchers make these critical decisions with confidence. When the FDA evaluates clinical trial data for new medications, p values help determine whether observed results represent real effects or mere coincidence. Understanding what is p value empowers students to interpret research findings, analyze data validity, and make evidence-based conclusions across multiple disciplines. Watch the full video on JoVE Coach to master this concept with expert-led visuals and step-by-step explanations.
The p value represents one of the most crucial concepts in inferential statistics, serving as the bridge between sample data and population-level conclusions. At its core, a p value quantifies the probability of observing your actual test results—or something even more extreme—assuming the null hypothesis is completely true. This seemingly simple definition carries profound implications for how we interpret research findings across disciplines from clinical medicine to educational psychology.
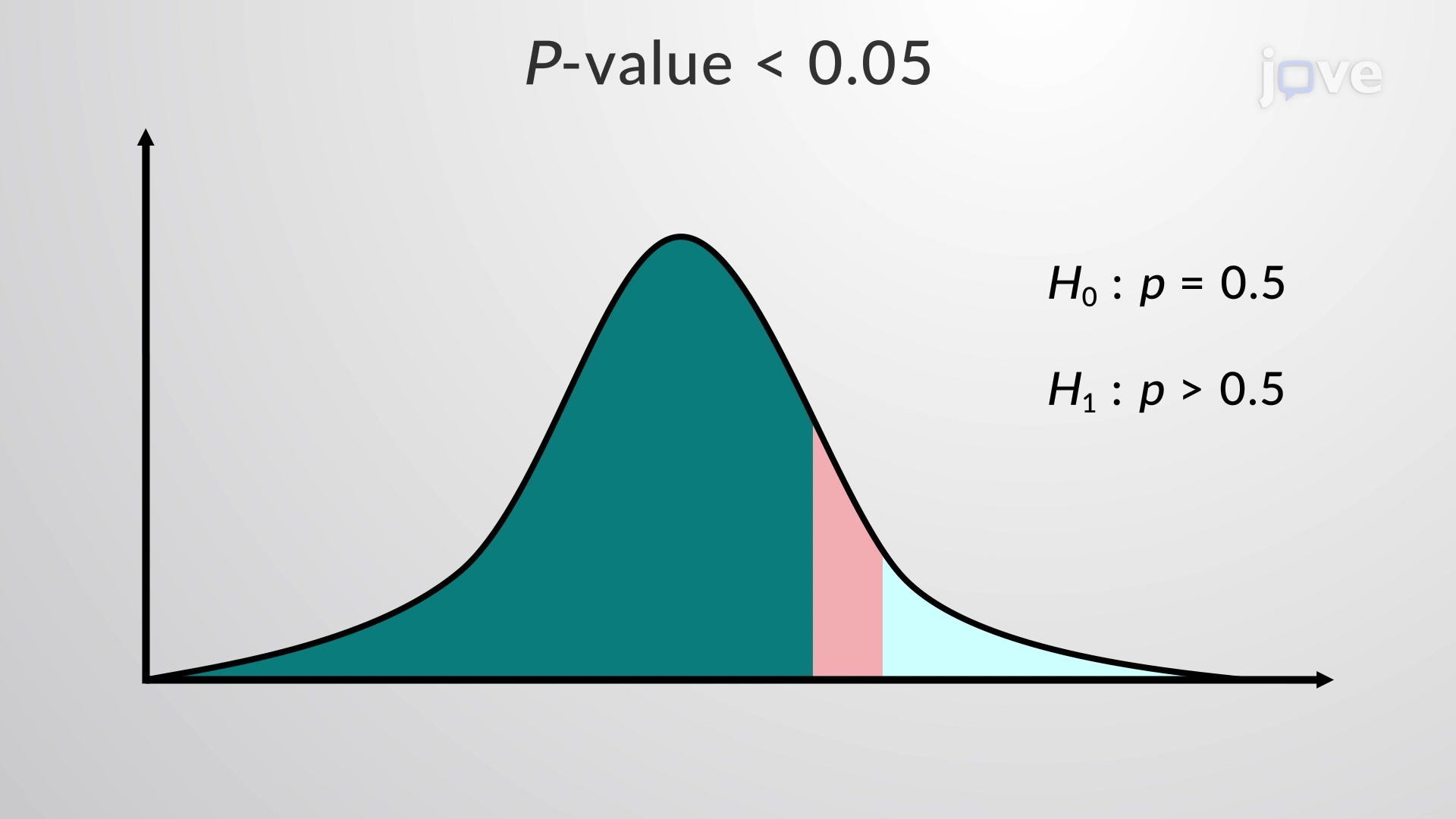
When researchers conduct hypothesis tests, they calculate a test statistic from sample data that follows a known probability distribution. The p value emerges as the area under this distribution curve, extending from the test statistic value toward the tail(s) of the distribution. For instance, if a pharmaceutical company tests whether their new cholesterol medication reduces LDL levels more effectively than existing treatments, they might observe a test statistic of 2.3 in a normal distribution. The p value would represent the probability of getting a test statistic of 2.3 or higher purely by random chance, assuming the new drug has no real effect.
This interpretation directly connects to the p value definition that students encounter in AP Statistics, college-level biostatistics courses, and standardized exams like the MCAT. The smaller the p value, the stronger the evidence against the null hypothesis, because it suggests that observing such extreme results by chance alone would be highly unlikely.
The conventional significance level of 0.05 serves as a widely accepted threshold in academic research and clinical trials. When a p value falls below this benchmark, researchers typically reject the null hypothesis and conclude that their findings are "statistically significant." However, this binary approach requires careful interpretation. A p value of 0.049 doesn't represent dramatically stronger evidence than 0.051—the difference lies in crossing an arbitrary but useful decision boundary.
Consider how the Centers for Disease Control and Prevention (CDC) evaluates vaccine effectiveness studies. Researchers might compare infection rates between vaccinated and unvaccinated groups, calculating p values to determine whether observed differences exceed what random variation could reasonably explain. These statistical decisions directly influence public health policy and medical recommendations affecting millions of Americans.
P value calculations vary depending on whether researchers conduct one-tailed or two-tailed tests. In one-tailed tests, researchers predict the direction of their effect and calculate p values using either the left or right tail of the distribution. Two-tailed tests, more conservative by nature, split the significance level across both tails and are particularly common in exploratory research where the direction of effects remains uncertain.
Students preparing for college statistics courses or the AP Statistics exam should understand these distinctions, as test questions frequently require identifying appropriate tail configurations based on research scenarios and alternative hypotheses.
Frequently Asked Questions
A p value tells you how likely it is to get your research results (or something even more extreme) if there's actually no real effect happening—just random chance. Think of it as asking: "If I flip a supposedly fair coin 100 times and get 65 heads, what's the probability this could happen with a truly fair coin?" A very small p value (like 0.02) suggests your results probably aren't due to chance alone.
AP Statistics frequently tests p value interpretation through multiple-choice scenarios where you must identify correct conclusions from given p values and significance levels. College placement exams often include questions about when to reject null hypotheses based on p value comparisons. The MCAT includes p value questions in its psychology and sociology sections, particularly regarding research methodology and study interpretation.
Both indicate statistical significance at the 0.05 level, but p = 0.003 provides much stronger evidence against the null hypothesis than p = 0.03. The smaller p value suggests that observing such extreme results by chance alone would be about 10 times less likely. However, statistical significance doesn't automatically mean practical importance—you still need to consider effect sizes and real-world relevance.
Clinical researchers use p values to determine whether new treatments show genuine improvements over existing therapies or placebos. For example, if a cancer treatment study yields p = 0.01 when comparing survival rates, researchers can conclude there's only a 1% chance that observed differences occurred purely by random variation. This statistical evidence helps support FDA approval decisions and influences treatment protocols nationwide.
You can absolutely master p value concepts in standard high school statistics or AP Statistics without calculus prerequisites. The key lies in understanding probability concepts and basic hypothesis testing logic rather than complex mathematical computations. Most statistics software handles the actual calculations, so focus on interpreting results and understanding what p values tell you about your data.
Practice interpreting p values in context rather than just memorizing formulas. Work through scenarios where you must decide whether to reject null hypotheses, explain what different p values mean in plain English, and identify appropriate significance levels for various research situations. Create flashcards connecting p value ranges (like p < 0.001, p = 0.045) with their practical interpretations and evidence strength levels.
Build on your p value foundation by studying confidence intervals, which provide complementary information about effect sizes and precision. Explore Type I and Type II errors to understand the limitations of hypothesis testing, then advance to power analysis and effect size measures like Cohen's d. These concepts work together to provide a more complete picture of statistical evidence than p values alone.
Critics argue that p values can be misleading when used in isolation, particularly because they don't indicate effect size magnitude or practical significance. The "p-hacking" problem occurs when researchers manipulate analyses to achieve significant p values, and the arbitrary 0.05 threshold can lead to over-interpretation of borderline results. Modern statistical practice emphasizes reporting p values alongside confidence intervals, effect sizes, and replication studies for more robust conclusions.
Related Micro-courses



Related Subjects











